The Progressive Artificial Neural Network (PANN™) represents a fundamentally new paradigm in neural network design and training that breaks from traditional gradient-based learning. Inspired by biological neural architectures and underpinned by patented corrective weight distributions, PANN™ enables orders-of-magnitude faster training and real-time adaptability on CPUs, GPUs, and other hardware while maintaining high accuracy for classification, recognition, and prediction tasks. By eliminating the need for extensive iterative training cycles and supporting scalable, efficient learning even with very large datasets, PANN™ opens the door to high-performance AI applications across industries without the heavy computational costs typical of conventional artificial neural networks.
In classical neural networks, training is based on various versions of the ‘gradient descent’ method, widely used in mathematics, which requires a huge number of iterative computation cycles, while the training time grows exponentially with the amount of data used for training. In addition, one of the most unpleasant properties of such networks is that it’s almost impossible to ‘update’ their training or ‘retrain’ them — any change, no matter how small, in a system that has already been trained for a long time requires an equally long new training.
Because of all this, building and running such neural networks requires the use of very powerful computers for training, a lot of highly paid programmers, a lot of expensive computer time, and electricity. Consequently, this leads to very expensive and slow developments in the advent of improving such networks, due to the long testing times of experimental iterations. That’s exactly why such developments are currently almost completely monopolized by industry giants.
Our keystone invention, the Omega Neuron™, made it possible to apply a fundamentally new training method that doesn’t require many iterations, providing an almost linear dependence of PANN™ training time on the amount of data. The more difficult the task and the larger the amount of data, the greater the gap in the learning rate compared to any other modern (convolutional, etc.) neural network. This allows for the very rapid development of such networks and products based on them, both replacing existing ones and creating completely new ones.

The use of PANN™ will greatly reduce the cost of creating and operating computer centers. At the same time, the reliability of data storage and protection from hackers and viruses will increase… All this is of particular importance for the implementation of large and extra-large databases, as well as indexed and non-indexed search systems in those databases. PANN™ would also be very useful in the development of unmanned systems for all types of transport. PANN™ also allows creating new products, for example, highly efficient personal training systems, a ‘personal doctor’, or even an ‘Alter Ego’ (second self, the ideal secretary and agent on computer networks), etc.
PANN™ realizes advantages of ANN predicted by science.
The Progressive Artificial Neural Network incorporates recent discoveries in neuroscience. It operates similarly to a natural neural network. The benefits of this similarity open the path to competitive opportunities for our customers.
PANN™’s novel architecture and training algorithm resolve many of the problems in existing ANNs. It can run on various devices: CPUs, GPUs, programmable microchips, memristor chips, optical microprocessors, etc., while improving and expanding their operational capabilities.
PANN™ realizes ANN advantages predicted by science. It enables:
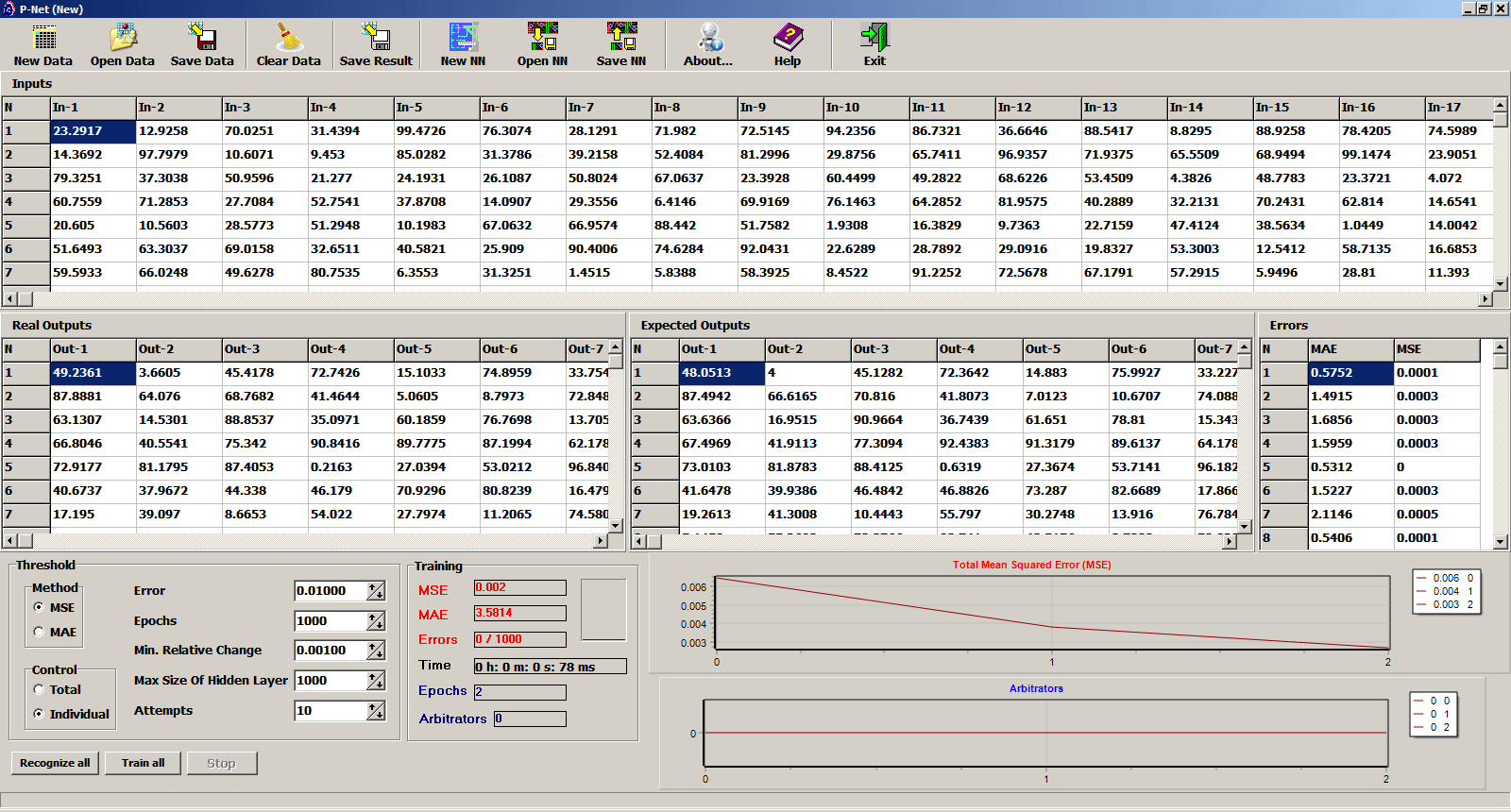
- High speed training with high accuracy for approximation, classification, and interpolation.
- Training on CPU is at least 3 000 times faster in comparison with existing ANN
- Training with one GPU is 200 000 times faster and proportional to the number of GPUs
- 100%-parallel computation; linear increase in training speed with additional GPUs.
- Batch training of the entire training set: weight correction after every epoch of images, not after every image. Recognition of the entire batch of images, not of a single image, one after another.
- Ability to train the network with additional images without retraining the entire network.
- It is reliable and resistant against network paralysis.
PANN™ can be implemented in both digital and analog forms, which creates additional advantages.
PANN™ software
PANN™ allows creating really smart software with high processing speed and unlimited amount of processed information. In addition:
- PANN™ is scalable, can be built in any size.
- PANN™ architecture and training algorithm have been discovered within biological analogs.
- Complex calculations are not necessary.
- Multiple repeating calculations are not necessary.
- Calculations and weight correction are performed using matrix algebra. (US Patent 9,390,373)
PANN™ can replace existing ANN and be used in development of the new advanced software for:
- Big and super big data;
- Fast performance;
- Processing unindexed data;
- Data protection;
- High reliability of the system;
- Solving unsolved problems.
PANN™ on Graphical Process Units
PANN™ is extremely fast on Graphical Process Units (GPU). This makes it possible to create a Supercomputer based on both GPUs and PANN™. Market of GPUs supercomputers is already about $18B.
Market is ready for this:
- Many supercomputer development companies use GPUs for parallel calculations, thus increasing operational speed. For example, Cray, IBM, Dell, and HPE.
- Some companies use GPU for ANN speed increasing. NVidia, for example, uses GPU to increase ANN speed 20+ times in comparison with CPU.

What makes all this possible.
PANN™ and its key features
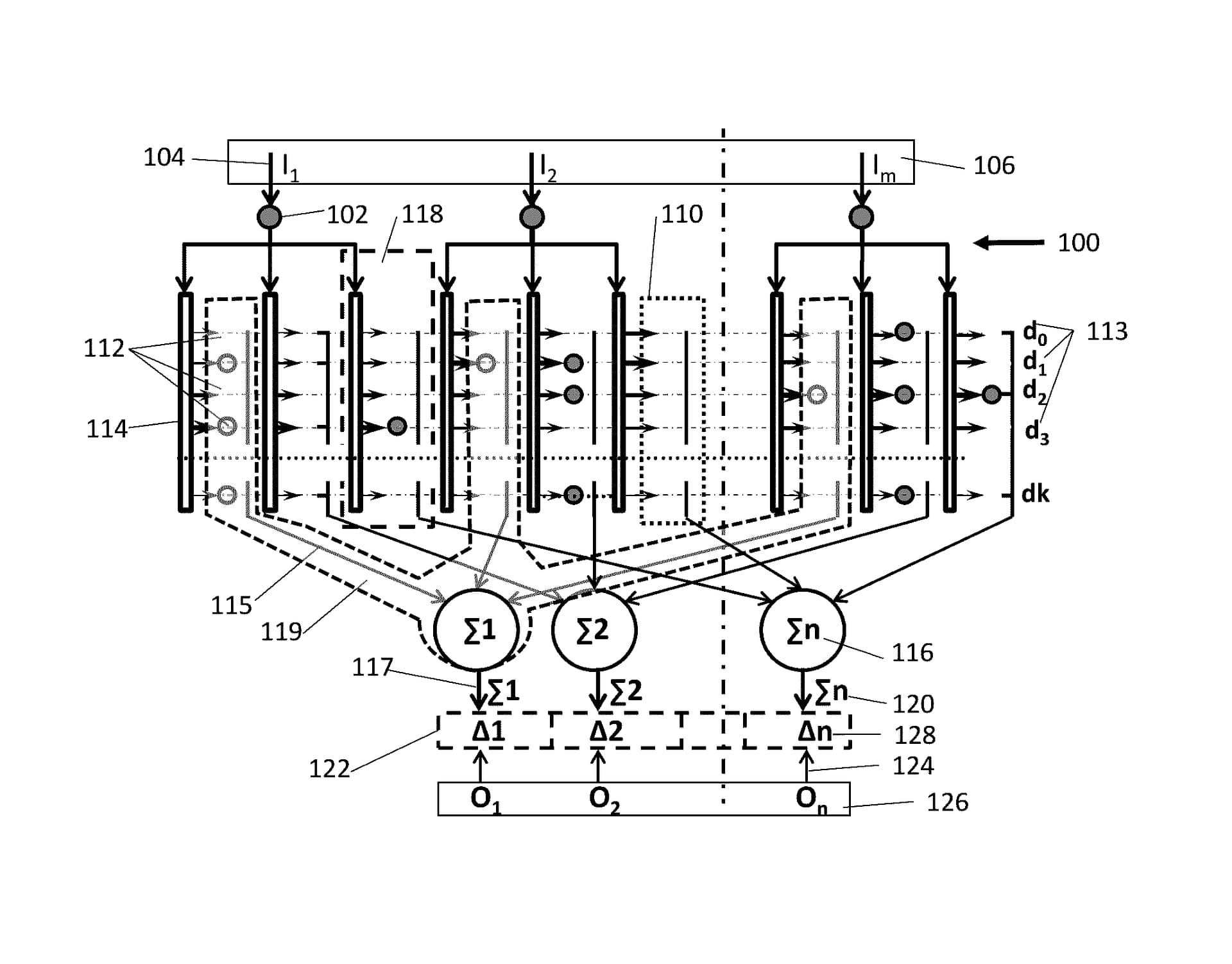
PANN™ new features include a distributor and a host of weights at each synapse.
US Patent 9,390,373
Input signals activate proper weights on a synapse. Distributor selects one or more weights depending on input signal magnitude and the information on selected weight value is sent to neuron.
As a result, PANN™ weight correction, i.e., training, is accomplished with a single-step operation of error compensation during the retrograde signal. This takes into account only the information received by the neuron from its synapses during training.
Training PANN™ with the next image does not depend on its training with the previous image. Complete compensation of training error is provided for each image used in training. Thus, calculations and weight correction may be performed using matrix algebra while complex and repeating calculations are not necessary.
In its basic variant, PANN™ provides correction of all weights that contribute to the error on a particular neuron; correction is provided by using the same value for all active weights. It has no activation function (or has a linear activation function), which drastically simplifies and reduces calculations.
These advantages enable a thousand-fold increase in PANN™ training speed.
Discover Progress patents